Problem Formulation
In our application setting, two types of RSUs are deployed along different road segments: corridor RSUs (C-RSUs) and crossroad RSUs (X-RSUs). As C-RSUs collect IID data from vehicles traveling along the same segment, conventional federated learning methods (e.g., FedAvg) can be effectively applied to aggregate model updates across all or a subset of these nodes. However, the presence of X-RSUs introduces significant data heterogeneity, as these nodes encounter diverse traffic flows and varying semantic contexts. In such cases, naive aggregation of model updates from out-of-distribution (OOD) sources may severely impair model performance. To address this challenge, we propose a decentralized gossip learning framework that incorporates OOD awareness into the aggregation process. We name our proposed work as GOOD, emphasizing its features.
Why Gossip Learning?
Traditional federated learning frameworks rely heavily on centralized servers for model aggregation, making them vulnerable in scenarios with intermittent or unreliable connectivity—common in remote or rural transportation settings. In contrast, gossip learning offers a decentralized alternative where RSUs can asynchronously exchange model parameters directly with neighbors, enhancing robustness and eliminating single points of failure. This peer-to-peer paradigm is particularly well-suited for intelligent transportation systems, where edge nodes often operate under unstable network conditions and encounter highly heterogeneous data distributions that centralized approaches struggle to handle effectively.
Why OOD Detection?
In intelligent transportation systems, RSUs deployed across diverse road environments often encounter data that varies significantly in distribution due to differences in location, traffic patterns, and environmental context. Without proper handling, aggregating model updates from such out-of-distribution (OOD) sources can lead to negative transfer, degrading the overall model performance. OOD detection is therefore critical in enabling each RSU to identify whether incoming model updates align with its local data distribution. By incorporating OOD awareness into the learning process, edge nodes can selectively trust and aggregate only those updates that are statistically compatible, thereby improving personalization, stability, and the overall robustness of decentralized model training.
Proposed GOOD Framework
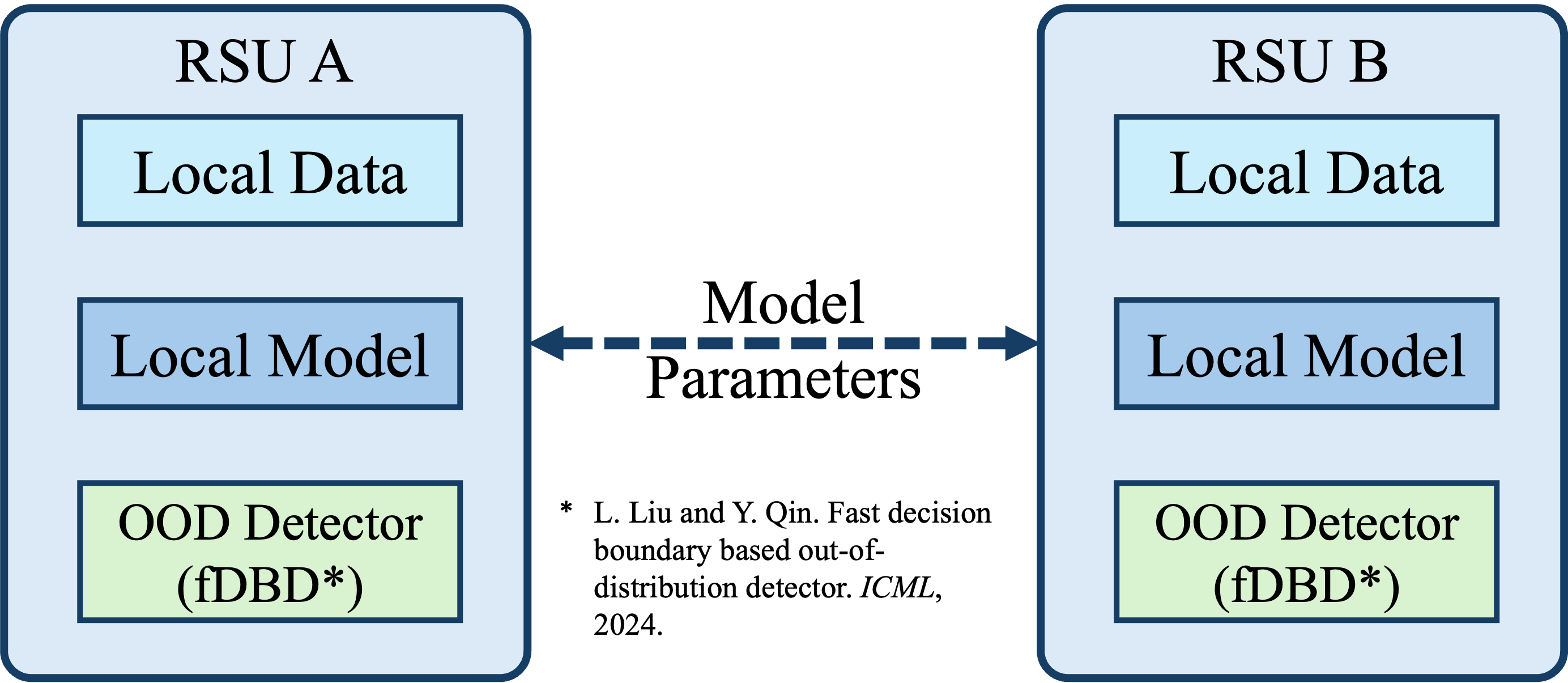
Our proposed GOOD framework is designed to address the challenges of decentralized learning under heterogeneous data distributions. To this end, each RSU in the GOOD learning scheme is equipped with a lightweight OOD detector, termed fDBD, which enhances model robustness and accuracy in distributed environments. Unlike traditional OOD detection methods that often rely on complex auxiliary models and significant computational overhead, fDBD provides a closed-form analytical estimation of feature distances. This design enables efficient OOD detection with minimal memory and storage requirements, making it highly suitable for resource-constrained edge devices.
Main Loop of GOOD
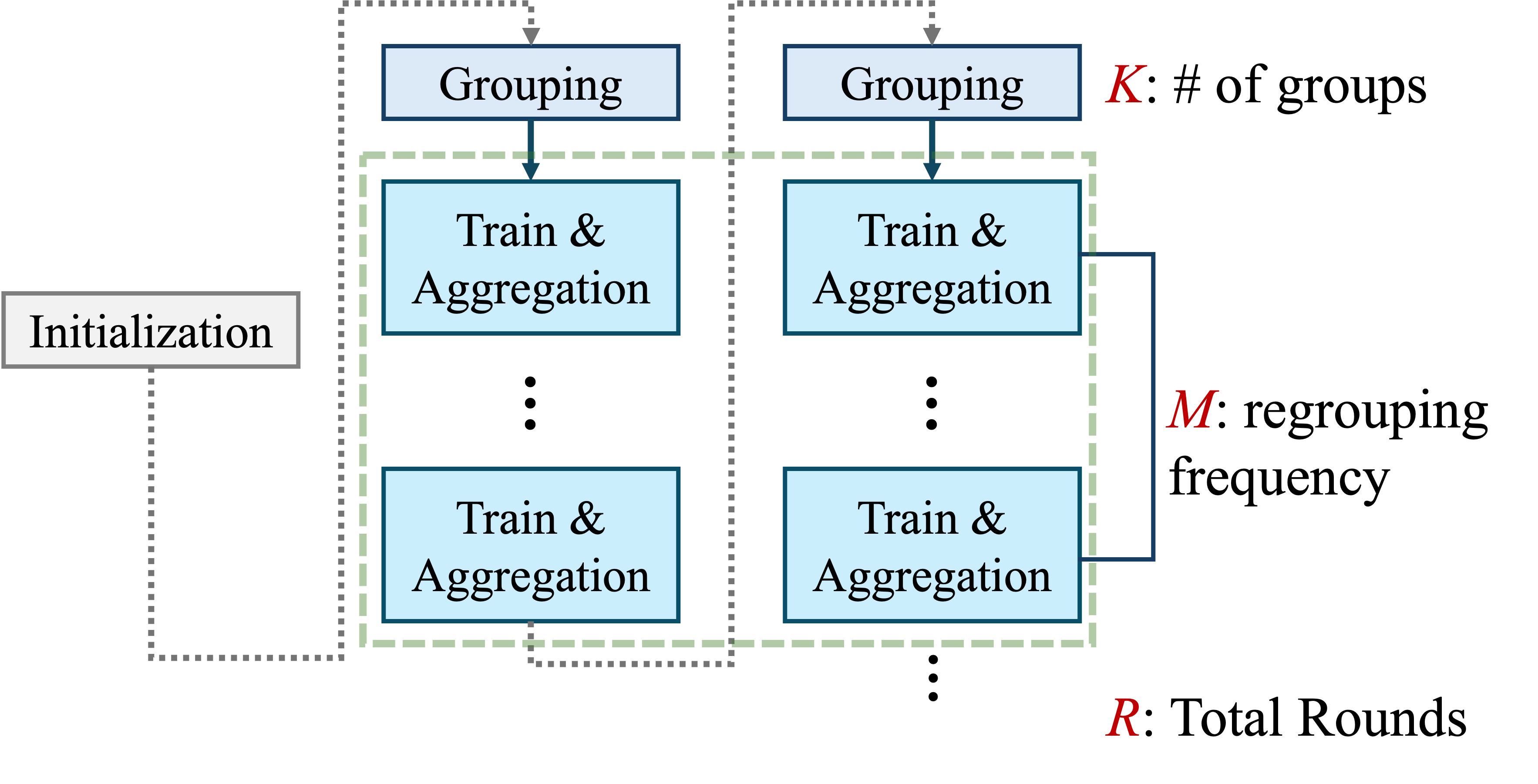
Initially, RSUs are randomly partitioned into K clusters. Within each group, training is performed locally, followed by model parameter exchange and aggregation after a predefined number of local epochs. The choice of K serves as a design parameter that balances model personalization and collaborative learning: overly homogeneous groups may lack data diversity, while overly heterogeneous groups risk aggregating misaligned updates.
At regular intervals, determined by a parameter M, RSUs temporarily pause training and aggregation to evaluate group composition based on OOD scores. Groups are then dynamically reconfigured to better reflect underlying data distributions. This process continues for a total of R rounds. To maintain consistency with centralized federated learning terminology, one round here is defined as the completion of both local training and aggregation by each RSU.
OOD-Based Decentralized Grouping Mechanism
The key insight of grouping mechanism is to determine the data heterogeneity based on the scores calculated by each RSU’s fDBD. The calculation method of the score is shown as follows. Intuitively, it quantifies whether RSU i would consider RSU j’s data distribution to be in-distribution (ID) or OOD relative to RSU i’s own data. A higher score suggests that RSU j’s data is ID with respect to RSU i; while lower scores imply OOD data.

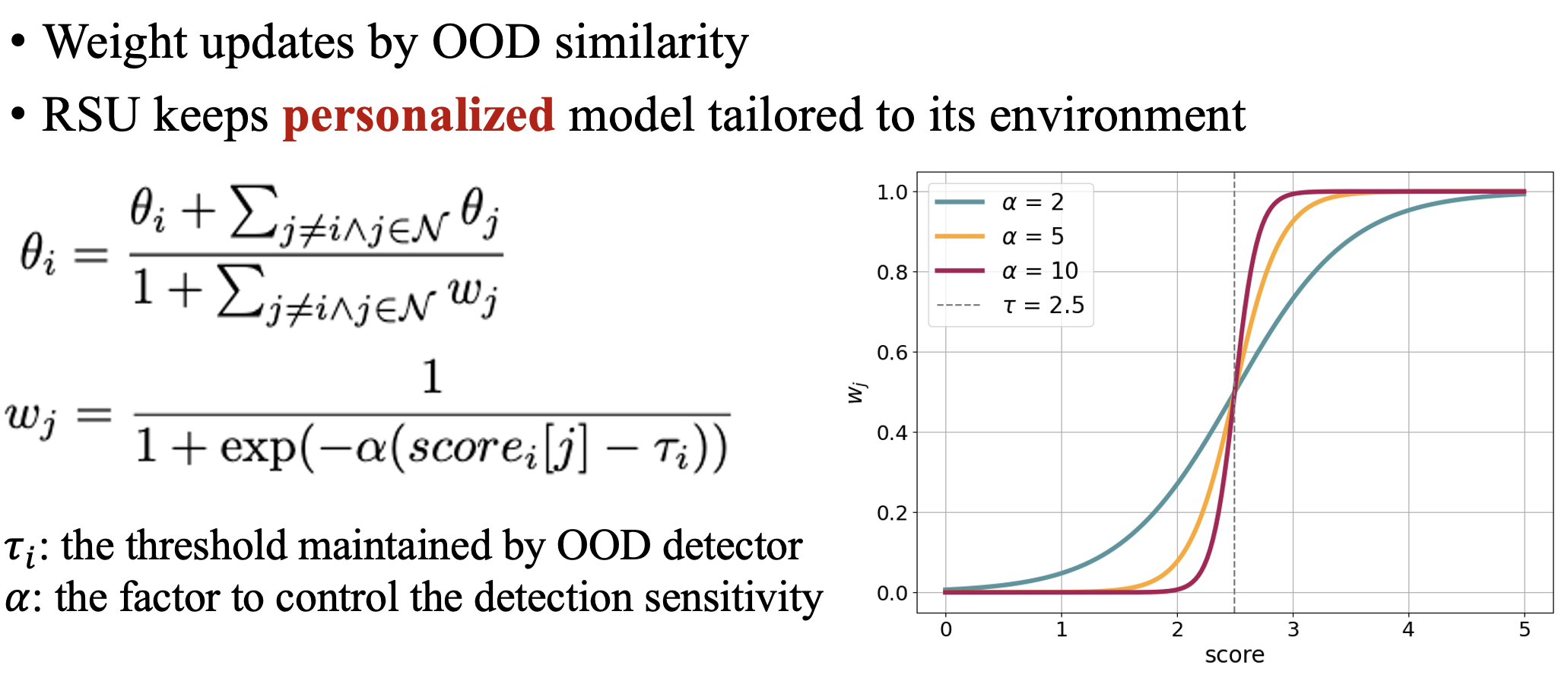
OOD-Aware Aggregation
The model aggregation is also guided by OOD scores. It is worth mentioning that, although aggregation is performed among nodes within the same group, we preserve OOD awareness during the process to mitigate potential grouping errors and provide each node with a more tailored model, acknowledging that their local data distributions may not be strictly in-distribution.