Experimental Setup
To simulate the non-IID conditions commonly encountered in real-world heterogeneous distributed environments, we employ two distinct image classification datasets—CIFAR-10 and SVHN—which naturally exhibit divergent data distributions. Both datasets are first balanced to equal sizes and then partitioned into equal-sized subsets, each assigned to a corresponding node. Each node is equipped with a ResNet-18 model and a customized fDBD detector. During training, each node performs one local epoch per round, using cross-entropy loss as the objective function. The Adam optimizer is used with a learning rate of 0.001. In our setup, we deploy 10 nodes, with five having access to CIFAR-10 and the remaining five to SVHN, and set K=2. All methods are implemented on Ubuntu 22.04 LTS, running on an Intel i9-13900H CPU, 32 GB RAM, and an NVIDIA RTX 4070 GPU. The experiments are conducted using Python 3.10 and PyTorch 2.6 version.
In addition, during the evaluation phase, we adopt two commonly used network topologies in gossip learning scenarios: ring and fully-connected. These topologies represent typical communication patterns among edge nodes, where the ring topology ensures limited and structured neighbor interactions, while the fully-connected topology enables more extensive information exchange by allowing each RSU to communicate with all others. By evaluating our framework under both settings, we demonstrate its adaptability and effectiveness across varying levels of communication connectivity.
Effectiveness of GOOD
We first analysis the effect to GOOD by setting different hyperparameters, namely sensitivity factor $\alpha$ and the regrouping frequency $M$. Specifically, $\alpha$ controls the sensitivity of model aggregation based on OOD scores, while $M$ determines how frequently RSUs are regrouped during training. In the following experiments, the number of model transmissions is defined as the total count of model send or receive operations across all clients throughout training, with each operation counted once.
We conducted experiments under both ring and fully connected topologies. Notably, across both topologies, moderate settings such as $\alpha=5$ and $M=5$ consistently achieve higher accuracy and more stable convergence. These results suggest that maintaining a proper balance between aggregation sensitivity and regrouping frequency is essential to maximizing the benefits of OOD-aware gossip learning. Compared with the CFL baseline, our method delivers superior performance, highlighting the advantages of decentralized and adaptive collaboration.
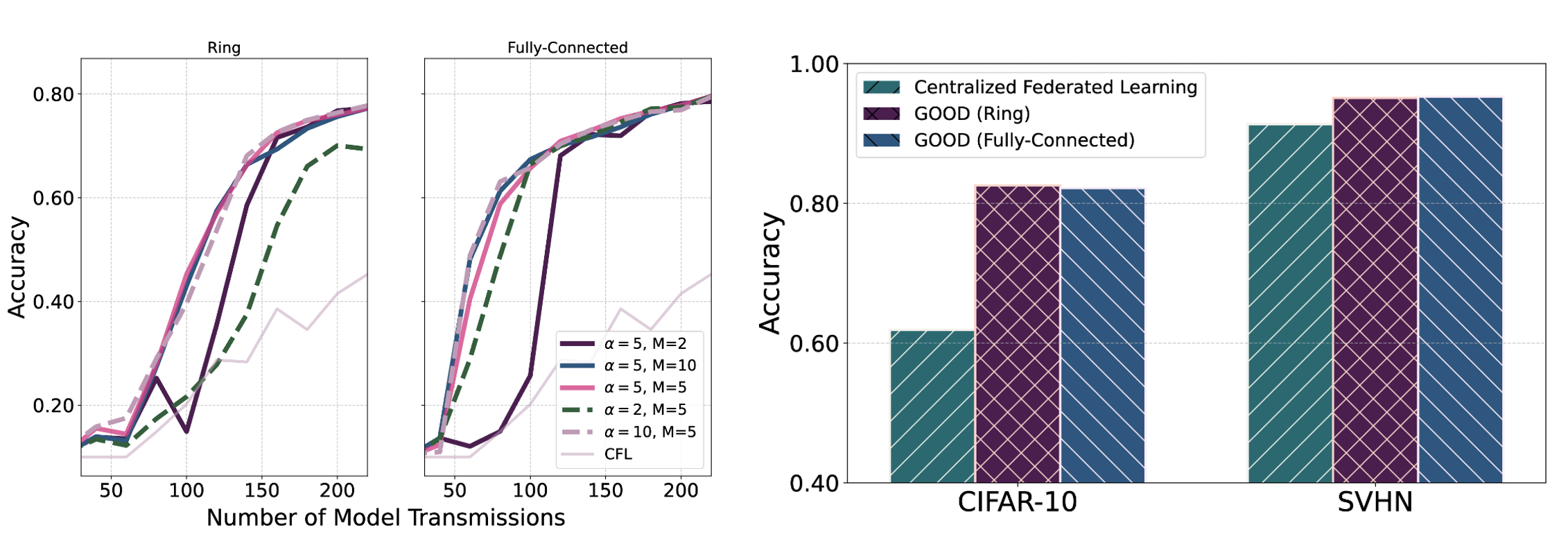
To fairly evaluate the final performance of each learning framework under equal communication cost, we compare the accuracy after a total of 600 model transmissions. To achieve so, we set the total rounds $R=30$ for both CFL and ring topology in GOOD, while $R=15$ for fully-connected topology. For the CFL baseline, we use the final global model and evaluate it separately on the test sets of CIFAR-10 and SVHN. Note that the global model is not distributed back to clients at this stage; the evaluation is purely centralized.
In contrast, for our proposed GOOD method, each RSU maintains a personalized local model. Therefore, we evaluate each local model individually on both unforeseen CIFAR-10 and SVHN test sets and report the average accuracy across all clients. This provides a fair comparison that reflects the collective system performance without relying on a centralized aggregation step. As shown in figure, GOOD achieves higher average accuracy on both datasets compared to CFL, demonstrating the effectiveness of gossip learning with OOD-guided grouping and aggregation.